
Top 8 Algoritmos de Machine Learning: Tudo que Você Precisa Saber
Como escolher o algoritmo de Machine Learning certo para o seu projeto


O universo do Machine Learning (aprendizado de máquina) está em constante evolução e tem transformado a maneira como interagimos com a tecnologia.
De recomendações de filmes a diagnósticos médicos, os algoritmos de machine learning são os responsáveis por aprender a partir de dados e gerar soluções inteligentes e automatizadas.
Mas, com tantas técnicas disponíveis, como saber qual escolher?
Este é o primeiro post de uma série que vai explorar os principais algoritmos de machine learning. A cada novo artigo, vamos detalhar um algoritmo específico, explicando seu funcionamento, melhores aplicações e como você pode usá-lo em seus próprios projetos.
Vamos começar entendendo os conceitos básicos que fundamentam essa tecnologia.
O que é Machine Learning?
Machine learning (em português, aprendizado de máquina ou aprendizagem de máquina) é uma área da inteligência artificial (IA) que permite que os computadores aprendam com dados, sem a necessidade de uma programação explícita.
Em vez de seguir regras fixas, os sistemas de machine learning identificam padrões nos dados e usam esses padrões para fazer previsões ou tomar decisões.
Tipos de Machine Learning
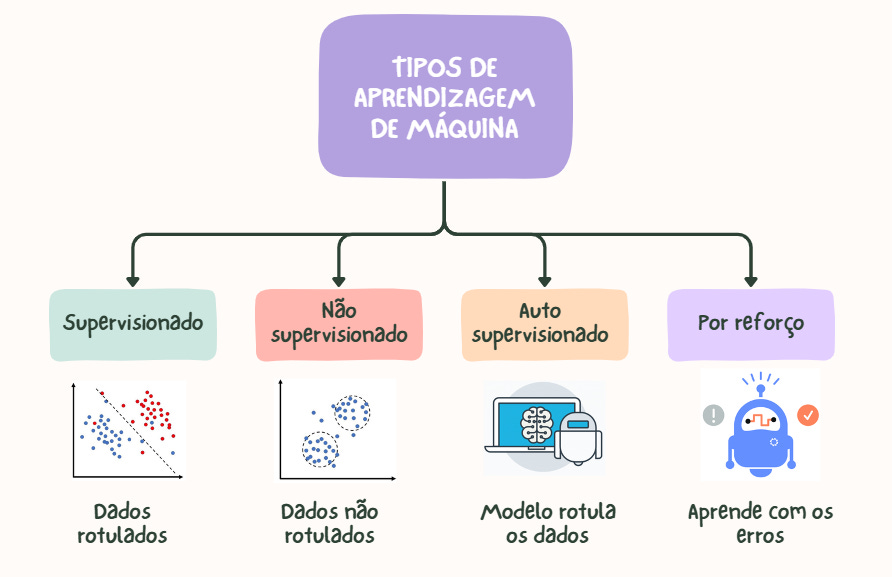
Machine learning pode ser dividido em três categorias principais, cada uma com características distintas e aplicações específicas.
O aprendizado auto-supervisionado não vou abordar aqui, vamos falar dele em outro momento :)
A escolha do tipo de aprendizado a ser utilizado depende do problema que você está tentando resolver e dos dados que tem à disposição.
As três principais abordagens são:
1. Aprendizado Supervisionado
No aprendizado supervisionado, o algoritmo aprende a partir de dados rotulados (ou anotados). Ou seja, o modelo é treinado com exemplos onde a entrada e a saída desejada já são conhecidas.
O objetivo é fazer com que o modelo aprenda a prever a saída correta para novas entradas, baseando-se no padrão identificado nos dados de treinamento.
Exemplos de Aplicações:
Classificação: Identificar se um e-mail é spam ou não, com base em um conjunto de exemplos rotulados de e-mails.
Regressão: Prever o valor de uma variável contínua, como o preço de uma casa com base em características como tamanho e localização.
Vantagens:
O modelo tem uma “orientação clara” sobre o que aprender, já que possui exemplos com respostas definidas.
Alta precisão, especialmente quando há muitos dados rotulados disponíveis.
Desvantagens:
Requer um grande número de dados rotulados, o que pode ser um desafio em alguns casos.
O modelo pode ter dificuldade em generalizar para novos dados que não se encaixam bem nos padrões identificados nos dados de treinamento.
2. Aprendizado Não Supervisionado
Diferente do aprendizado supervisionado, no aprendizado não supervisionado, o algoritmo trabalha com dados não rotulados, ou seja, não anotados.
O modelo tenta identificar padrões ou estruturas ocultas nos dados, como agrupamentos ou associações, sem ter uma resposta específica para prever.
Exemplos de Aplicações:
Clustering: Agrupar clientes com base em suas compras em comum, sem saber previamente quais grupos existem.
Redução de dimensionalidade: Reduzir o número de variáveis em um conjunto de dados, preservando as informações mais relevantes.
Vantagens:
Não requer dados rotulados, o que torna o processo mais flexível e adequado quando não se tem respostas conhecidas.
Pode revelar padrões ocultos nos dados que não seriam facilmente percebidos.
Desvantagens:
A interpretação dos resultados pode ser mais difícil, já que não há um "rótulo" claro para os dados.
Pode ser mais desafiador validar a precisão ou a eficácia do modelo, já que não há uma resposta pré-definida para verificar.
3. Aprendizado por Reforço
O aprendizado por reforço é uma abordagem mais dinâmica, em que um agente aprende a tomar decisões através de interações com o ambiente.
Ao invés de ser treinado com dados ou respostas predefinidas, o agente recebe feedback baseado em recompensas ou punições, dependendo das ações que executa.
Exemplos de Aplicações:
Jogos: Treinar agentes para jogar videogames ou jogos de tabuleiro, como o xadrez ou o Go.
Robótica: Ensinar robôs a realizar tarefas complexas, como caminhar ou pegar objetos.
Vantagens:
Pode ser usado em ambientes onde as respostas não são predefinidas e são aprendidas através de tentativa e erro.
Ideal para problemas em que a sequência de decisões é importante (como em jogos e robótica).
Desvantagens:
Requer um ambiente de treinamento interativo e muitas vezes é mais complexo de implementar.
Pode ser mais demorado para alcançar resultados significativos, pois depende do feedback contínuo.
Cada tipo de algoritmo tem suas próprias vantagens e é aplicável a diferentes cenários. Compreender qual abordagem usar em seu projeto é crucial para o sucesso da implementação de um modelo eficaz.
O que vem por aí: Algoritmos que vamos explorar
Agora que você conhece os diferentes tipos de machine learning, vamos dar uma olhada nos 8 algoritmos que vamos explorar ao longo da série.
Cada um desses algoritmos tem suas próprias características e é aplicável a uma variedade de problemas. Ao longo dos próximos posts, vamos mergulhar no funcionamento de cada um deles e entender quando e como usá-los para obter os melhores resultados, começando com o aprendizado supervisionado.
1. Regressão Linear
Vamos começar com um dos algoritmos mais simples e poderosos: a regressão linear. Ele é usado para prever valores contínuos e é ideal para situações onde existe uma relação direta entre as variáveis. Imagine prever o preço de uma casa com base em sua metragem quadrada e localização.
2. Regressão Logística
A regressão logística é uma extensão da regressão linear, mas voltada para problemas de classificação binária. Ela é amplamente utilizada para prever a probabilidade de ocorrência de um evento, como em problemas de detecção de fraude, diagnóstico médico ou classificação de e-mails como spam. Vamos entender como ela pode ser aplicada de maneira eficaz em situações de previsão binária.
3. Árvore de Decisão
As árvores de decisão são ferramentas versáteis e intuitivas. Elas ajudam a tomar decisões dividindo os dados em vários caminhos, como um fluxograma. É um dos algoritmos mais fáceis de interpretar, tornando-o muito popular em problemas de classificação e previsão.
4. Random Forest
Random Forest é um algoritmo de conjunto que combina várias árvores de decisão para melhorar a precisão e reduzir o risco de overfitting. Ele é ideal para problemas mais complexos, onde você precisa de maior precisão e robustez.
5. Máquinas de Vetores de Suporte (SVM)
O SVM é um poderoso algoritmo para classificação e regressão, e é especialmente útil quando temos classes que estão bem separadas. Ele encontra a linha ou hiperplano que divide os dados da maneira mais eficiente, maximizando a margem entre as classes. Ideal para situações onde a precisão é crucial.
6. K-Nearest Neighbors (KNN)
KNN é um dos algoritmos de classificação mais simples e eficazes. Ele classifica os dados com base na proximidade dos pontos em relação aos seus vizinhos mais próximos. Vamos explorar como ele pode ser aplicado a problemas de classificação, como reconhecimento de padrões ou diagnóstico médico.
7. Redes Neurais
As redes neurais são o núcleo de muitas inovações modernas em IA, como reconhecimento de voz e imagem. Elas são inspiradas no funcionamento do cérebro humano e são extremamente poderosas para resolver problemas complexos, como a classificação de imagens e o processamento de linguagem natural.
8. K-Means (Aprendizado Não Supervisionado)
No aprendizado não supervisionado, o K-Means é um dos algoritmos mais populares para agrupamento de dados. Ele divide os dados em clusters (grupos) com base em suas semelhanças. Se você precisa segmentar clientes em diferentes grupos, o K-Means pode ser a solução perfeita.
Cada um desses algoritmos será detalhado nos próximos posts da série, com exemplos e dicas para implementar cada técnica de forma eficaz.
Caso você queira ter acesso ao Colab (Notebook) com o código prático desses algoritmos em funcionamento, acesse: https://elisaterumi.substack.com/p/notebooks
Não perca!! 🩷