


Random Forest: Como Melhorar a Precisão Com Várias Árvores de Decisão
Com Random Forest, cada árvore contribui para uma decisão mais robusta e precisa


Olá pessoal!
Continuando a série “Top 8 Algoritmos de Machine Learning: Tudo que Você Precisa Saber”, hoje é a vez de explorarmos Random Forest ou “Florestas Aleatórias“.
No último post, vimos como as árvores de decisão oferecem uma maneira intuitiva e visual de tomar decisões baseadas em dados.
Agora imagina combinar várias árvores de decisão para melhorar a precisão e evitar overfitting? Isso é possível com Random Fores, uma técnica poderosa e versátil para tarefas de classificação e regressão.
Mas o que exatamente é o Random Forest, como ele funciona e por que é tão amplamente utilizado? Vamos explorar essas questões neste artigo.
O que é Random Forest?
O Random Forest é um algoritmo de aprendizado supervisionado baseado em um conjunto de árvores de decisão. Ele utiliza o conceito de ensemble learning, onde múltiplos modelos (neste caso, árvores de decisão) trabalham juntos para obter previsões mais precisas.
Ensemble em Machine Learning é uma técnica que combina múltiplos modelos para melhorar a precisão e robustez das previsões. Ao invés de confiar em um único modelo, o ensemble utiliza a "sabedoria das multidões", onde a combinação de várias predições de diferentes modelos leva a um desempenho mais forte e confiável.
Cada árvore na floresta dá uma previsão, e o Random Forest combina essas previsões para tomar uma decisão final. Para tarefas de classificação, o resultado final é determinado pela votação da maioria; para regressão, é calculada a média das previsões.
Como o Random Forest Funciona?
Random Forest constrói várias árvores de decisão em paralelo, mas com dois ingredientes-chave que introduzem diversidade e reduzem o risco de overfitting:
Bootstrap Aggregation (Bagging):
Em vez de treinar todas as árvores no mesmo conjunto de dados, o algoritmo seleciona subconjuntos aleatórios do conjunto de treinamento, com substituição. Isso significa que cada árvore é treinada em uma amostra ligeiramente diferente dos dados originais.Seleção Aleatória de Features:
Durante o treinamento de cada nó da árvore, o algoritmo escolhe um subconjunto aleatório de features (atributos ou características) em vez de considerar todas as features disponíveis. Isso impede que uma única feature domine a tomada de decisão.
Com essas estratégias, o Random Forest combina o poder de várias árvores individuais para criar um modelo robusto e preciso.
Vantagens do Random Forest
Robustez contra Overfitting:
Devido ao uso de múltiplas árvores e técnicas de aleatoriedade, o Random Forest é menos propenso a superajustar o modelo aos dados de treinamento.Acurácia:
Ele frequentemente supera algoritmos mais simples, especialmente em problemas com muitas features ou dados ruidosos.Facilidade de Uso:
O Random Forest requer pouca preparação dos dados e pode lidar com dados categóricos e numéricos sem necessidade de escalonamento.Importância das Features:
O algoritmo fornece uma métrica de importância das features, permitindo identificar quais variáveis têm maior impacto na previsão.Versatilidade:
Funciona bem para classificação, regressão e até tarefas como detecção de anomalias.
Desvantagens do Random Forest
Apesar de suas vantagens, o Random Forest também apresenta alguns desafios:
Complexidade Computacional:
Modelos com muitas árvores podem ser computacionalmente intensivos e consumir mais memória.Interpretabilidade Reduzida:
Embora as árvores individuais sejam fáceis de interpretar, a combinação de centenas ou milhares de árvores dificulta a explicação do modelo.
Aplicações Práticas
O Random Forest é amplamente utilizado em setores como:
Saúde:
Diagnóstico médico com base em sintomas ou exames laboratoriais.
Predição de doenças com base em dados genômicos.
Finanças:
Análise de crédito e detecção de fraudes.
Previsão de preços de ativos.
E-commerce:
Recomendação de produtos.
Análise de churn (perda de clientes).
Ciências Ambientais:
Previsão de desastres naturais.
Modelagem de ecossistemas.
Processamento de Linguagem Natural (PLN):
Classificação de textos e análise de sentimentos.
Implementação Prática em Python
Abaixo está um exemplo simples de como usar Random Forest com a biblioteca scikit-learn.
Neste exemplo, vamos usar o dataset Iris, um conjunto de dados clássico em aprendizado de máquina, utilizado para tarefas de classificação. Ele contém 150 amostras de flores da espécie Iris, com 4 características (comprimento e largura da sépala e pétala) para cada amostra, divididas em três classes: setosa, versicolor e virginica.

1 - Treinamento
Crie um novo arquivo no Jupyter Notebook e cole esse código para obter o dataset e realizar o treinamento:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Carregar o dataset Iris
data = load_iris()
X = data.data
y = data.target
# Dividir os dados em treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Criar e treinar o modelo
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Fazer previsões e avaliar o modelo
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Acurácia do modelo: {accuracy:.2f}")2 - Inferência
Agora, podemos fazer inferêcnia com o modelo treinado. Vamos supor que temos duas flores Iris no qual queremos descobrir a espécie. Extraímos o comprimento e largura da sépala e pétala e vamos enviar para o modelo.
# Novos dados para fazer a inferência
novos_dados = [[5.1, 3.5, 1.4, 0.2], # Exemplo 1
[6.7, 3.1, 4.7, 1.5]] # Exemplo 2
# Fazer a previsão
previsoes = model.predict(novos_dados)
# Exibir as previsões
print("Previsões para os novos dados:", previsoes)
Resultado:
Previsões para os novos dados: [0 1]Nosso modelo fez previsões para os dois novos exemplos e as classes previstas para esses exemplos são 0 e 1, que correspondem aos índices das classes no conjunto de dados, no caso setosa e versicolor.
3 - Visualizar a Importância das Features
Agora vamos ver quais características do conjunto de dados são mais importantes para o modelo.
import matplotlib.pyplot as plt
import numpy as np
# Obter a importância das features
importancia = model.feature_importances_
# Criar o gráfico de importância das features
features = data.feature_names
indices = np.argsort(importancia)
plt.figure(figsize=(8, 6))
plt.title("Importância das Features")
plt.barh(range(len(indices)), importancia[indices], align="center")
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel("Importância")
plt.show()
Resultado:
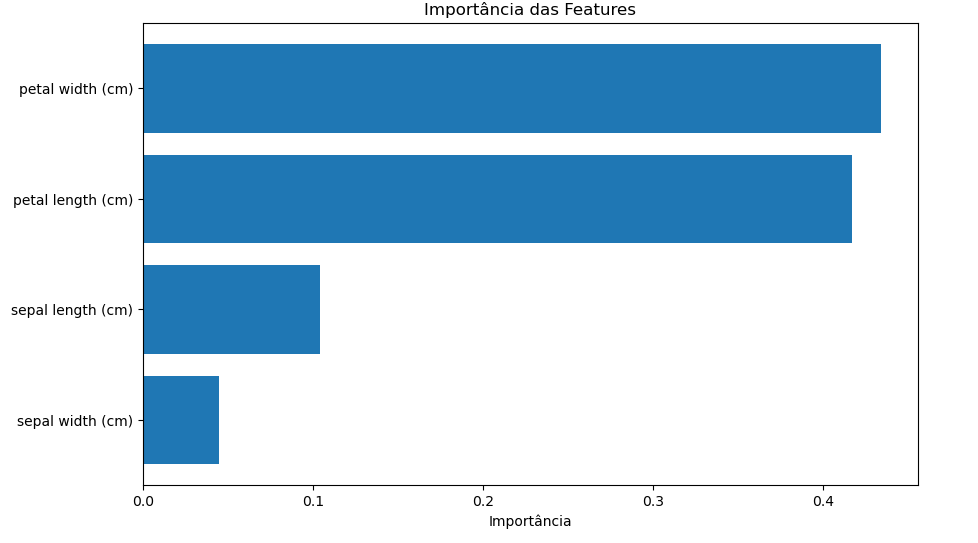
Este gráfico mostra a importância relativa de cada feature no modelo. O eixo y contém os nomes das variáveis (features), e o eixo x mostra a importância de cada uma delas para as decisões do modelo.
4 - Matriz de Confusão
A matriz de confusão ajuda a avaliar a performance do modelo, mostrando como ele classificou corretamente ou incorretamente as amostras de cada classe.
from sklearn.metrics import confusion_matrix
import seaborn as sns
# Gerar a matriz de confusão
matriz_confusao = confusion_matrix(y_test, y_pred)
# Plotar a matriz de confusão
plt.figure(figsize=(8, 6))
sns.heatmap(matriz_confusao, annot=True, fmt="d", cmap="Blues", xticklabels=data.target_names, yticklabels=data.target_names)
plt.title("Matriz de Confusão")
plt.xlabel("Predição")
plt.ylabel("Real")
plt.show()
Resultado:

A matriz de confusão mostra o número de acertos e erros do modelo para cada classe. As células diagonais indicam os acertos, enquanto as células fora da diagonal mostram os erros.
A nossa matriz indica um desempenho excelente do modelo de classificação, ou seja, o modelo teve uma taxa de acerto de 100%.
Conclusão
O Random Forest é uma ferramenta poderosa e flexível, amplamente usada em diversos domínios devido à sua robustez, precisão e facilidade de uso. Embora não seja perfeito para todos os casos, é um excelente ponto de partida para muitos problemas de aprendizado supervisionado.
Se você está explorando o mundo do aprendizado de máquina, vale a pena experimentar o Random Forest e descobrir como ele pode trazer valor aos seus projetos!
No próximo post, vamos explorar Máquinas de Vetores de Suporte (SVM).
Até a próxima!! 🩷