


K-Means: Agrupando Dados de Forma Eficiente
Agrupar dados nunca foi tão simples – descubra o poder do K-Means


Dando sequência na série “Top 8 Algoritmos de Machine Learning: Tudo que Você Precisa Saber“, chegou a vez de conhecermos o K-means!
O K-Means é um dos algoritmos de aprendizado de máquina mais populares para clusterização, ou seja, agrupamento de dados.
Simples e eficiente, ele é amplamente utilizado em diversas áreas, como análise de dados, segmentação de clientes, compressão de imagens e muito mais.
O código no Colab você encontra em: https://elisaterumi.substack.com/p/notebooks
O que é o K-Means?
O K-Means é um algoritmo de aprendizado não supervisionado que organiza dados em K grupos. Ele funciona distribuindo pontos em clusters, minimizando a distância entre os pontos do cluster e seu centroide.
Para entender melhor como o K-Means funciona, é importante entender o que é aprendizado não supervisionado.
Aprendizado Não Supervisionado
No aprendizado não supervisionado, o modelo é treinado sem a presença de rótulos ou respostas conhecidas. Em vez de tentar prever um valor específico, o objetivo é identificar padrões ou estruturas nos dados. O algoritmo tenta encontrar agrupamentos ou associações nos dados de forma autônoma, sem a necessidade de informações externas.
Por isso, o K-Means é considerado um algoritmo de aprendizado não supervisionado: ele organiza dados em clusters (grupos) com base nas similaridades entre eles, sem que o usuário precise fornecer rótulos para os dados.
Como Funciona?
O processo do K-Means pode ser dividido em quatro etapas principais:
Definir o número de clusters (K).
Inicializar os centróides aleatoriamente.
Atribuir cada ponto ao cluster mais próximo.
Atualizar os centróides e repetir até a convergência.
Esse processo continua até que os centróides não mudem significativamente.
Vantagens
Simples de implementar e rápido para conjuntos de dados moderados
Funciona bem em dados bem separados
Boa escalabilidade para grandes volumes de dados
Desvantagens
O número de clusters precisa ser definido previamente
Sensível a valores iniciais (pode cair em mínimos locais)
Pode não funcionar bem com clusters de formatos não esféricos
Vamos codificar!
Agora que já vimos o que é K-means e como funciona, vamos colocar a mão na massa!
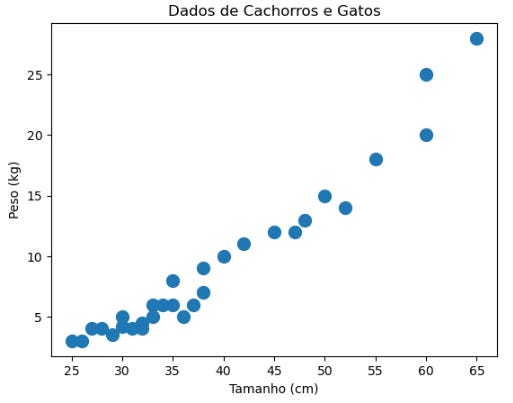
Vamos usar um dataset de exemplo com 30 exemplos, onde temos características simples de cachorros e gatos: tamanho (em cm) e peso (em kg). O objetivo é que o K-Means consiga agrupar os dados em duas classes: cachorros e gatos.
Código Python para criar o dataset e aplicá-lo no K-Means:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Criando um dataset simples com 30 exemplos
# Tamanho (cm), Peso (kg)
dados = np.array([
[40, 10], [35, 8], [45, 12], [50, 15], [60, 20], # Cachorros
[38, 9], [55, 18], [42, 11], [52, 14], [48, 13],
[60, 25], [38, 7], [37, 6], [65, 28], [47, 12],
[30, 5], [32, 4], [34, 6], [36, 5], [33, 6], # Gatos
[25, 3], [28, 4], [29, 3.5], [27, 4], [26, 3],
[30, 4.2], [31, 4], [35, 6], [33, 5], [32, 4.5]
])
# Criando o DataFrame
df = pd.DataFrame(dados, columns=['Tamanho (cm)', 'Peso (kg)'])
# Visualizando o dataset
plt.scatter(df['Tamanho (cm)'], df['Peso (kg)'], s=100, cmap='viridis')
plt.title("Dados de Cachorros e Gatos")
plt.xlabel('Tamanho (cm)')
plt.ylabel('Peso (kg)')
plt.show()
# Aplicando K-Means com 2 clusters (cachorros e gatos)
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans.fit(dados)
# Atribuindo os clusters aos dados
df['Cluster'] = kmeans.labels_
# Plotando os resultados
plt.scatter(df['Tamanho (cm)'], df['Peso (kg)'], c=df['Cluster'], s=100, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', marker='X') # Centrôides
plt.title("Cachorros vs Gatos: Resultado do K-Means")
plt.xlabel('Tamanho (cm)')
plt.ylabel('Peso (kg)')
plt.show()
# Exibindo os centros dos clusters
print("Centros dos Clusters:", kmeans.cluster_centers_)Resultado
Plotando os dados do dataset em um gráfico:
Resultado do K-means:

Explicação
Tamanho (cm) e Peso (kg) foram as duas características criadas para os exemplos de cachorros e gatos.
Cachorros tendem a ser maiores e mais pesados, enquanto gatos são geralmente menores e mais leves.
O algoritmo K-Means foi configurado para criar 2 clusters (um para cachorros e outro para gatos).
O gráfico mostra como o K-Means agrupa os dados, com os centróides dos clusters marcados em vermelho.
Inferência
Para fazer a inferência em uma nova instância, vamos usar esse código:
Continue a ler com uma experiência gratuita de 7 dias
Subscreva a Explorando a Inteligência Artificial para continuar a ler este post e obtenha 7 dias de acesso gratuito ao arquivo completo de posts.