


Gemma 3: O que há de novo no modelo multimodal da Google

A terceira geração da família de modelos Gemma, desenvolvida pela Google DeepMind, representa um avanço técnico significativo em direção a modelos multimodais, eficientes e acessíveis.
Hoje vamos nos aprofundar nas mudanças arquiteturais, capacidades ampliadas e impacto prático do Gemma 3, incluindo sua versão quantizada QAT (Quantization-Aware Training).
Com foco em uso on-device, compressão inteligente e entendimento de imagens e múltiplos idiomas, essa nova família marca uma evolução importante na linha de modelos abertos da Google.
Para ver o notebook Colab com um exemplo de inferênica no Gemma3, acesse: https://elisaterumi.substack.com/p/notebooks (procure por “Inferencia com Gemma3.ipynb”).
O que é o Gemma 3?
Gemma 3 é um modelo da nova geração da família Gemma, escalando de 1B a 27B de parâmetros, e agora com suporte multimodal (texto + imagem). Essa versão herda a arquitetura eficiente dos modelos anteriores, mas com otimizações específicas para suportar:
128K tokens de contexto (em modelos maiores)
compreensão de imagens via um encoder SigLIP adaptado
atenção intercalada local-global para reduzir uso de memória (KV-cache)
e uma nova tokenização multilíngue balanceada.
Principais novidades do Gemma 3
A seguir, você confere os destaques que tornam o Gemma 3 tão interessante para quem trabalha com IA:
Suporte multimodal (texto + imagem)
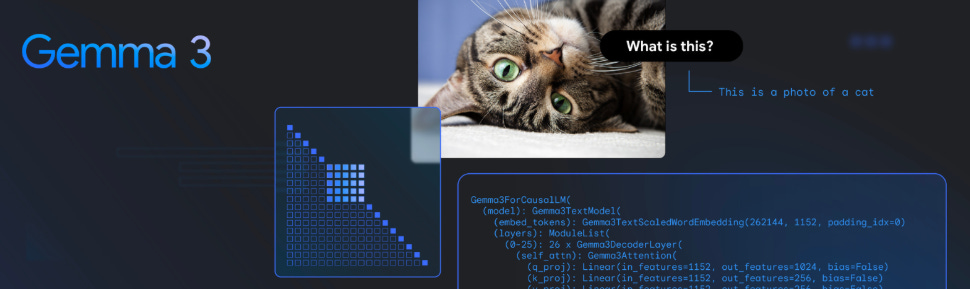
O Gemma 3 agora entende imagens! Ele incorpora um codificador visual baseado no SigLIP, ajustado especialmente para essa versão.
As imagens são processadas com uma técnica chamada Pan&Scan, que adapta diferentes proporções e resoluções para o modelo trabalhar com imagens quadradas de 896x896 pixels.
Essas imagens são convertidas em 256 vetores ("soft tokens") por um MultiModalProjector, o que reduz drasticamente o custo computacional na inferência.
Comparando com o PaliGemma 2:
O PaliGemma é melhor para tarefas como segmentação de imagem e detecção de objetos. Mas o Gemma 3 tem vantagens para tarefas multimodais gerais, chats multi-turn e generalização zero-shot.
Como o Gemma 3 entende imagens
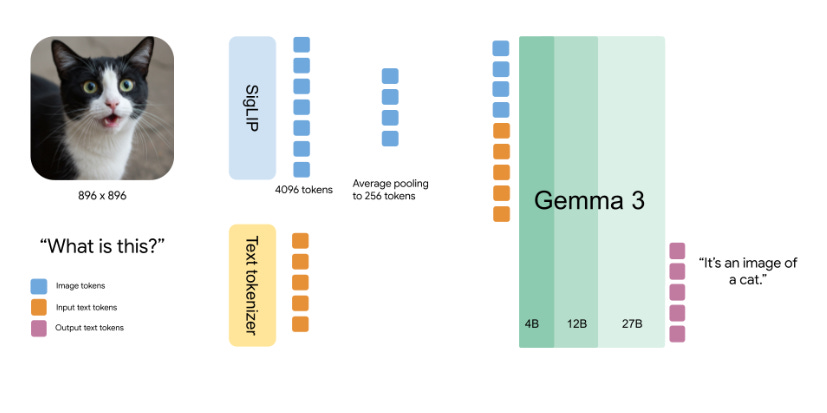
O modelo usa atenção bidirecional nas imagens, diferente da atenção unidirecional tradicional em texto.
Isso significa que cada "pedaço" da imagem se conecta com todos os outros simultaneamente, como montar um quebra-cabeça. Já no texto, como a tarefa é gerar a próxima palavra, a atenção precisa ser sequencial.
Eficiência e contexto estendido
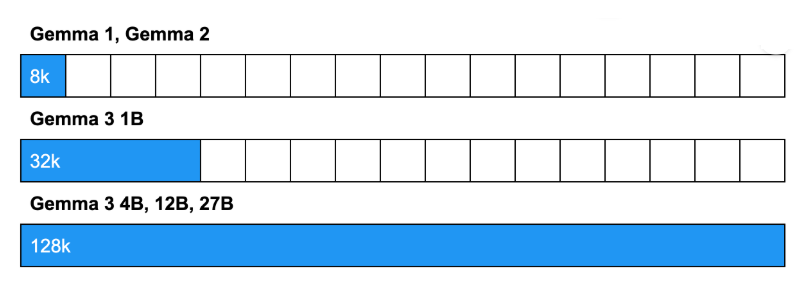
O Gemma 3 foi projetado para lidar com contextos longos de até 128 mil tokens nos modelos maiores (12B e 27B), o suficiente para analisar um romance inteiro, 500 imagens ou fazer análise de documentos extensos.
Como ele consegue isso?
Novo padrão de atenção intercalada (5:1): 5 camadas com atenção local + 1 camada com atenção global, em vez da alternância 1:1 do Gemma 2.
Menor uso de memória KV-cache: Isso é fundamental em aplicações de longo contexto.
Melhor “Multilinguismo”
O Gemma 3 adota o mesmo tokenizer usado no Gemini, com vocabulário de 262K tokens e baseado em SentencePiece.
A mistura de dados de pré-treinamento foi ampliada com maior variedade de idiomas (monolíngues e paralelos), resultando em:
melhor desempenho em idiomas de baixa representatividade
mais equilíbrio entre idiomas no output
menor viés anglocêntrico.
Importante: versões anteriores do tokenizer não são compatíveis com o Gemma 3.
Quer mais novidades de IA? Me siga no Linkedin e no Instagram!
Desempenho e impacto
O Gemma 3-27B chegou a ficar entre os 10 melhores modelos no LM Arena (abril de 2025)
Ele supera modelos maiores em vários benchmarks, mantendo eficiência para rodar em GPUs de consumo
A versão 1B-IT, apenas textual, é otimizada para dispositivos móveis e embarcados, tornando aplicações de IA mais acessíveis e privadas.
Nova versão quantizada (QAT)
A Google lançou também os modelos quantizados com QAT (Quantization-Aware Training), otimizados para rodar em GPUs de consumo, TPUs locais e dispositivos móveis.
Esses modelos, com peso em 4 bits, mantêm alto desempenho enquanto reduzem drasticamente:
consumo de memória (VRAM)
tempo de inferência
necessidade de energia.
Exemplo: o modelo Gemma 3 1B QAT pode rodar em celulares com NPU, edge devices ou laptops sem GPU dedicada.
O QAT foi implementado de forma integrada no processo de treinamento, evitando as perdas comuns de desempenho de quantizações pós-treinamento.
Os modelos quantizados estão disponíveis no HuggingFace e no Gemmaverse.
A versão quantizada pode ser executada no Google Colab, inclusive usando apenas a CPU.

Saída:
Eu sou Gemma, um modelo de linguagem grande criado pelo Google DeepMind. Sou um modelo de código aberto, amplamente disponível ao público. Fui treinado para receber texto e imagem como entrada e gerar texto como saída.
Eu sou um modelo de linguagem, então posso te ajudar com uma variedade de tarefas, como:
* Responder a perguntas
* Gerar texto criativo (poemas, roteiros, peças musicais, e-mails, cartas, etc.)
* Traduzir idiomas
* Resumir textos
* Escrever diferentes tipos de conteúdo
Eu estou sempre aprendendo e evoluindo, então minha capacidade de realizar tarefas pode mudar com o tempo.\n\nVocê pode me testar e me dar feedback para me ajudar a melhorar!Para ver o notebook Colab completo com o exemplo de inferência no Gemma3, acesse: https://elisaterumi.substack.com/p/notebooks (procure por “Inferencia com Gemma3.ipynb”).
Conclusão
O Gemma 3 representa um avanço importante na construção de modelos multimodais mais leves, eficientes e acessíveis.
Com visão computacional integrada, maior janela de contexto e melhorias multilíngues, ele oferece recursos de ponta sem exigir infraestruturas caras.
As versões quantizadas QAT completam o ecossistema, permitindo que essa tecnologia de ponta seja embarcada em celulares, dispositivos de borda, e ambientes com recursos limitados, sem perder desempenho.
Essa evolução abre portas para desenvolvedores e pesquisadoras criarem experiências mais ricas, responsivas e inclusivas em IA, mesmo em dispositivos com recursos limitados.
Os novos modelos estão disponíveis no Ollama (veja como usar Ollama aqui), no HuggingFace e Kaggle.
Espero que o artigo tenha sido útil e até a próxima! 💜
Obrigado pelo texto, sou programador mas vem bem leigo em LLMs
, então estou começando a molhar os pés usando N8N com Ollama para facilitar.
Testei o Gemma3 e notei que ele não tem função de utilizar Tools, no próprio site do Ollama notei que os modelos tem essas especificidades.
E muito complicado fazer o modelo ver mais versátil? Ter tools, vision, embedding?
Curiosidade de leigo que poderia estar perguntando ao chatGPT mas está tentando manter a oportunidade de ter interações sociais haha