

Do LoRA ao QLoRA: O próximo passo na personalização eficiente de LLMs

No post anterior, vimos como funciona LoRA, uma técnica que revolucionou o fine-tuning ao permitir que apenas uma fração dos parâmetros de grandes modelos de linguagem fosse treinada.
Uma solução elegante, eficiente e acessível para adaptar modelos como o LLaMA a novas tarefas com consumo reduzido de memória.
Agora, entramos na próxima fase dessa jornada: QLoRA.
O QLoRA (Quantized LoRA) dá um passo adiante ao combinar a ideia de adaptação com baixo custo com quantização extrema, reduzindo os pesos do modelo base para apenas 4 bits, sem perda significativa de performance.
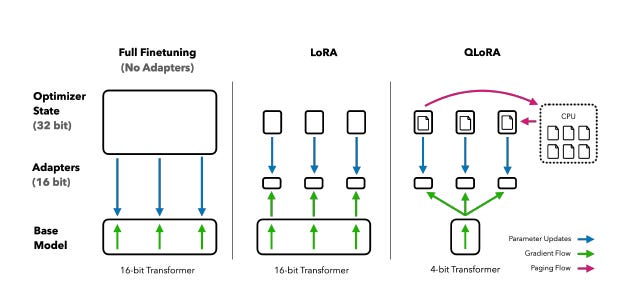
Qual o impacto disso na prática?
QLoRA permite:
Treinar modelos de até 65 bilhões de parâmetros em uma única GPU de 48GB
Obter resultados próximos (ou superiores) ao ChatGPT usando apenas dados abertos
Reduzir drasticamente o custo computacional e de energia do fine-tuning.
Como funciona?
QLoRA combina três avanços principais:
NF4 (NormalFloat 4-bit): um tipo de dado feito sob medida para pesos com distribuição normal, mais eficaz que os tradicionais FP4 e INT4.
Dupla quantização: até os fatores de quantização são quantizados, economizando ainda mais memória.
Paged Optimizers: evitam picos de memória durante treinamento em máquinas com recursos limitados.
Me acompanhe no LinkedIn e no Instagram pra mais conteúdos como esse! 😉
Aplicando QLoRA na prática
Quando falamos de QLoRA, estamos combinando duas técnicas poderosas: quantização em 4 bits com o BitsAndBytes e LoRA para um fine-tuning eficiente. A boa notícia? Isso se traduz em poucas linhas de código.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)Essa configuração ativa a quantização em 4 bits usando o formato nf4, mais preciso do que int4 e ideal para pesos com distribuição normal. A combinação com double_quant reduz ainda mais a memória usada, sem sacrificar desempenho.
Depois, basta passar essa configuração ao carregar o modelo base:
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)Com isso, já estamos com o modelo carregado em 4 bits, pronto para ser adaptado com LoRA.
👉 Para ver o código completo com um exemplo prático, acesse a área de Notebooks.
QLoRA é sobre autonomia
Técnicas como LoRA e QLoRA representam um grande avanço na forma como lidamos com fine-tuning de modelos de linguagem em larga escala.
Ao combinar quantização eficiente com adaptadores leves, QLoRA torna possível treinar modelos com bilhões de parâmetros usando infraestrutura acessível.
Isso representa um passo importante na democratização do acesso ao desenvolvimento de LLMs personalizados e de alta performance. O que antes exigia clusters de GPUs e orçamentos milionários, hoje pode ser feito no laboratório de uma startup, em um centro de pesquisa universitário, ou até mesmo, em alguns casos, no nosso notebook!
Se você trabalha com produtos baseados em LLMs, pesquisa acadêmica ou apenas quer experimentar fine-tuning localmente com recursos limitados, vale a pena explorar o QLoRA.
Github oficial: https://github.com/artidoro/qlora