


Criando um Chatbot com Ollama e Docker - Parte 2
Utilize o poder do Ollama com Docker para criar aplicações de inteligência artificial incríveis em sua máquina local.

Na primeira parte desta série, exploramos a instalação do Ollama e discutimos os primeiros passos para rodar modelos localmente.
Hoje, vamos criar uma aplicação de chatbot na prática, tirando proveito do Ollama com Docker.
Caso você não conheça Docker, acesse aqui um tutorial explicando os primeiros passos com essa ferramenta poderosa de conteinirização.
Preparando o Ambiente
Caso você não tenha lido a primeira parte da nossa série, recomendo que leia antes de iniciarmos, acessando aqui.
Para a aplicação que vamos construir, será necessário ter o Docker instalado no seu computador.
Vamos utilizar duas imagens Docker, uma contendo o Ollama e outra para a interface gráfica da nossa aplicação. Os comandos para fazer download das imagens Docker são:
docker pull ollama/ollama
docker pull ghcr.io/open-webui/open-webui:mainO primeiro comando baixa a imagem do Ollama, enquanto o segundo comando baixa a imagem do Open WebUI, uma interface de usuário para gerenciar e testar modelos de IA no Docker.
Executando Ollama via container
Agora que já obtivemos as imagens, vamos primeiramente iniciar o container com o Ollama na porta 11434, executando o comando abaixo no terminal ou cmd do Windows:
docker run -d -p 11434:11434 --name ollama_app ollama/ollamaAgora, vamos obter um modelo (LLM) para podermos conversar. Para isso, vamos acessar o container ollama_app e executar um comando para obter e executar o modelo llama3.1.
docker exec -it ollama_app ollama run llama3.1Nosso modelo está sendo baixado dentro do container, e após o download ter sido finalizado, já é possível interagir com o modelo.

Agora já podemos conversar com nosso LLM, utilizando Docker!

Executando a interface gráfica - Open WebUI
Para a interface da nossa aplicação de chatbot, vamos utilizar Open WebUI, uma interface projetada para rodar modelos de linguagem localmente em nosso computador.
Fácil de configurar com Docker, a plataforma permite integração com diversos modelos e suporta plugins para adicionar bibliotecas Python e funções avançadas, como tradução e busca em documentos. Para ver mais detalhes, acesse o site oficial.
Para executar o container com o Open WebUI, vamos executar:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainA partir de agora, a aplicação já está rodando na porta 3000. Para visualizar, acesse no seu navegador o endereço http://localhost:3000.
Baixando um modelo de linguagem
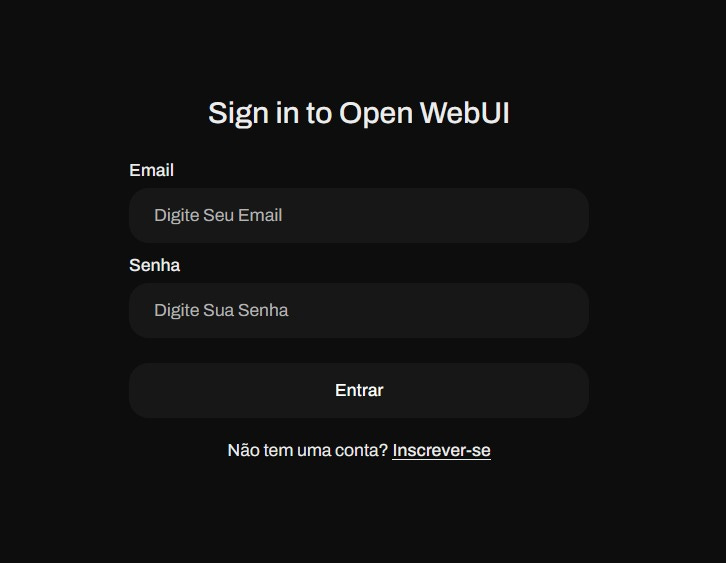
Agora que sua interface já está funcionando, crie uma conta para se logar e você já verá a tela de boas vindas.
Ao acessar pela primeira vez, é necessário criar um usuário, que será gravado apenas em sua aplicação local.
Para obter um modelo, clique no ícone do seu perfil e acesse as Configurações.
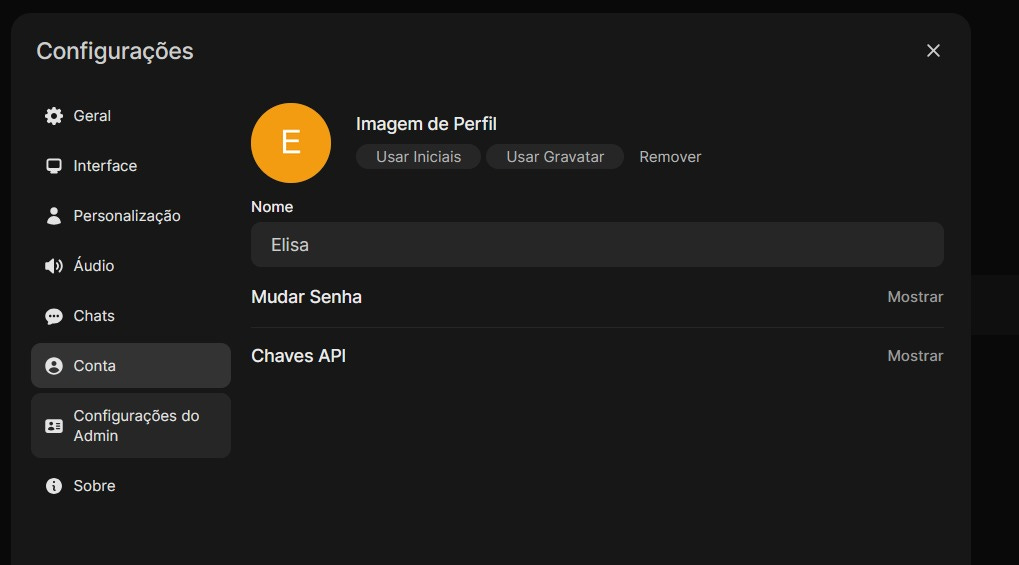
Acesse a opção Configurações do Admin:
Acesse o menu Modelos:
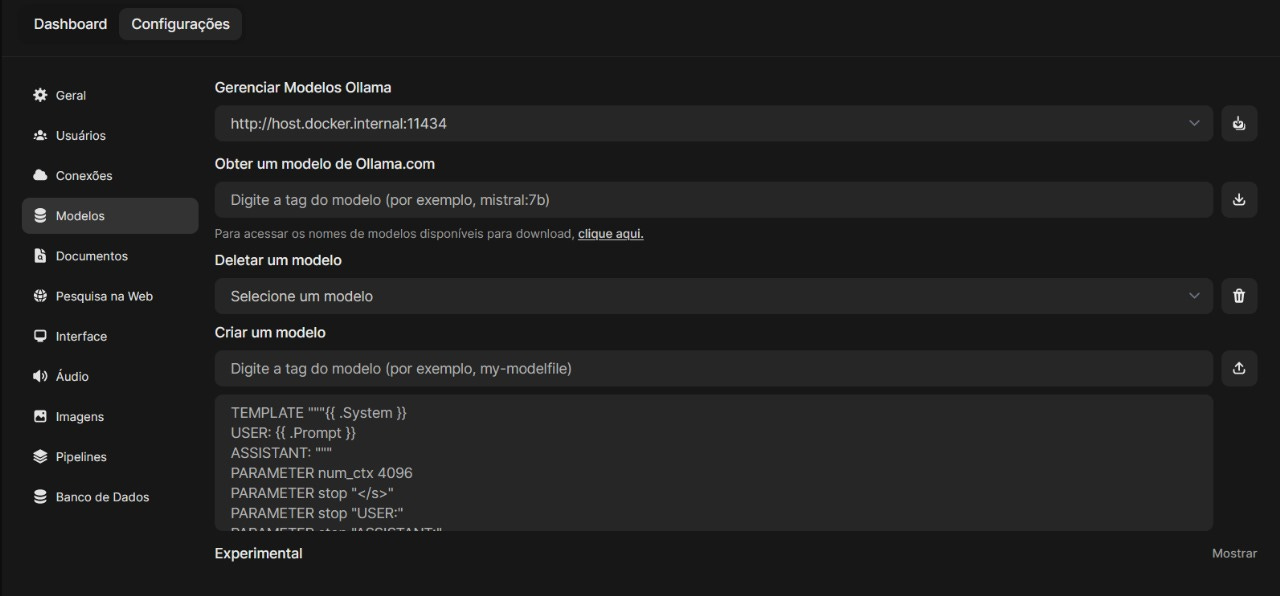
Na linha Obter um modelo de Ollama.com, informe qual modelo você quer obter. No nosso caso, vamos usar o Llama 3.2.

Conversando com o modelo
Se tudo ocorrer corretamente, a aplicação deve ter baixado o modelo que você indicou no passo anterior.
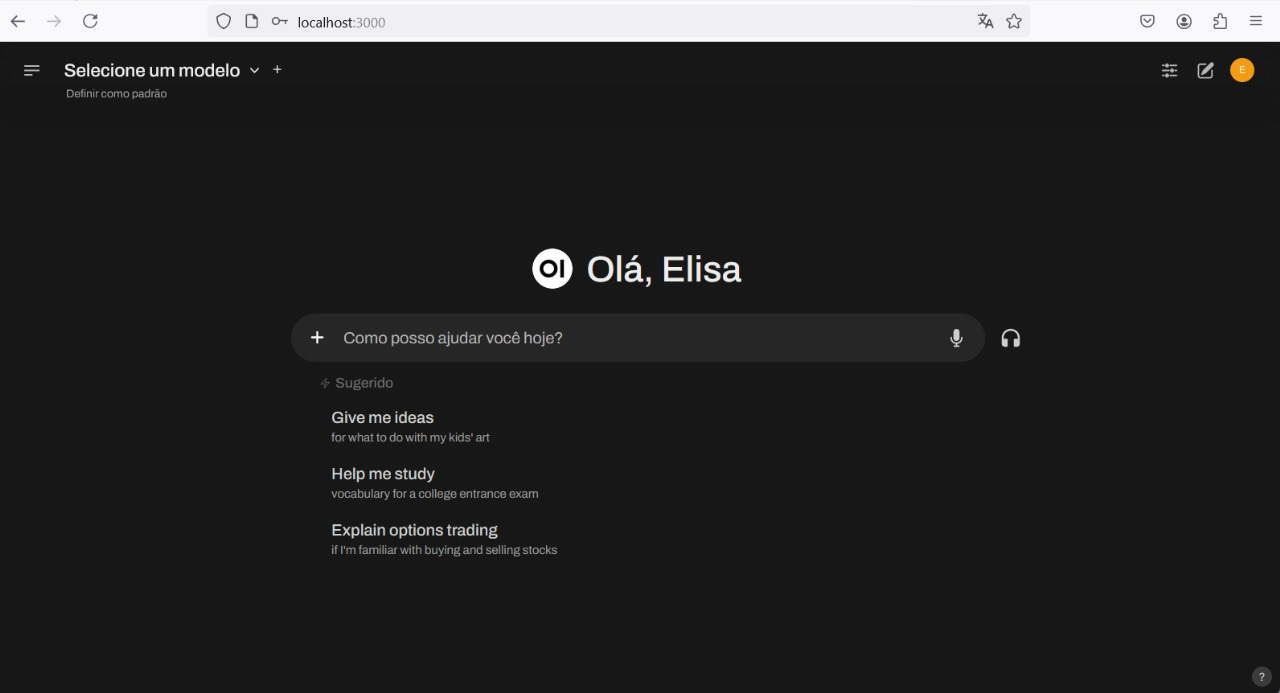
Para conversar com o modelo, basta voltar à tela inicial e selecioná-lo na barra de seleção de modelos, conforme a imagem abaixo:
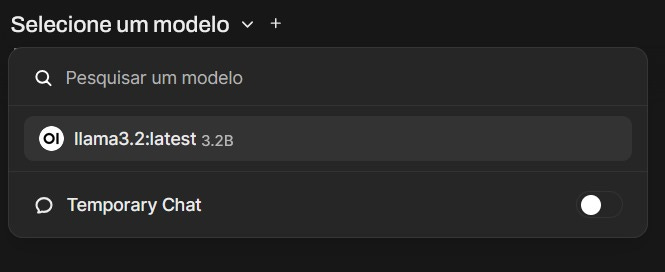
Com isso, você já pode conversar com seu modelo local, usando a interface gráfica!! 🥳
Para ver os containers que estão executando localmente, basta acessar no terminal ou cmd:
docker ps -aEle vai exibir a lista de containers, no nosso caso temos a interface com Open WebUI e o Ollama.
Caso você queira parar e remover os containers, basta executar:
docker stop ollama_app
docker rm ollama_app docker stop open_webui
docker rm open_webuiFim da segunda parte
Neste post, aprendemos a executar o Ollama com interface gráfica utilizando contêineres Docker.
No próximo post, vamos explorar como utilizar o Docker-Compose para gerenciar esses contêineres e também vamos ver um exemplo com um modelo multimodal.
Aguarde!! 🩷