
Gemini Embedding 2: Um modelo que entende texto, imagem, áudio e vídeo

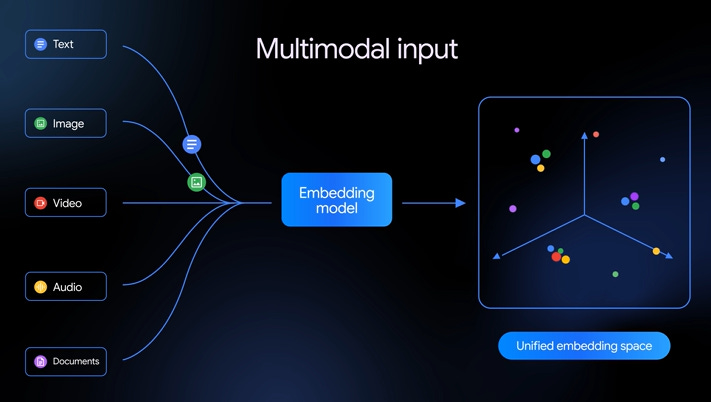
O Google acaba de dar um passo importante na evolução dos embeddings.
Com o lançamento do Gemini Embedding 2, passamos a ter um modelo nativamente multimodal; capaz de representar texto, imagem, áudio, vídeo e documentos no mesmo espaço vetorial.
Pode parecer apenas mais um modelo.
Mas não é.
Para entender o impacto disso, vamos primeiro relembrar o que são embeddings e para que servem.
Para mais novidades de IA, me siga no Linkedin e no Instagram ❤
Veja também:
O que são embeddings
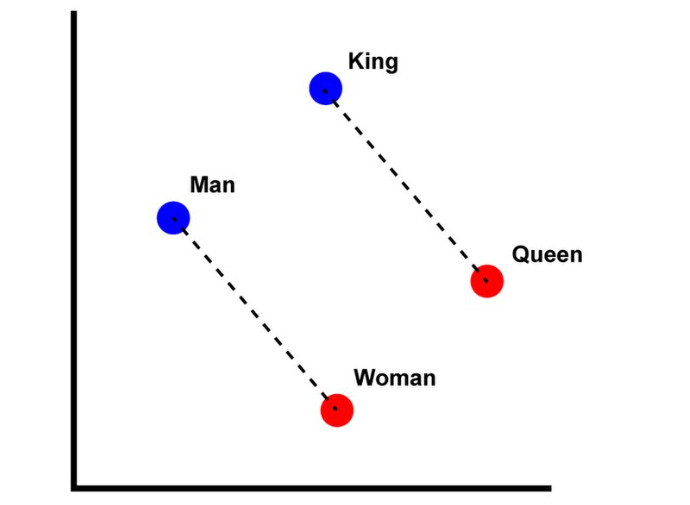
Embeddings são representações numéricas de dados.
Um texto, uma imagem ou um áudio deixam de ser apenas mídia e passam a ser vetores, ou seja, sequências de números que capturam o significado daquele conteúdo.
O ponto central não são os números em si, mas como eles se organizam.
E aí vem a ‘mágica”:
conteúdos parecidos ficam próximos no espaço vetorial
conteúdos diferentes ficam distantes
Isso permite transformar problemas complexos, como entender linguagem ou comparar imagens, em algo mais direto: medir distâncias entre vetores.
É essa propriedade que viabiliza aplicações como busca semântica (que vai além de palavras-chave), sistemas de recomendação mais precisos, agrupamento de dados e técnicas como RAG, que dependem de encontrar contexto relevante de forma eficiente.
Até aqui, nada muito novo.
A novidade: embeddings multimodais
Tradicionalmente, cada tipo de dado precisa de um modelo diferente, que gera embeddings em seu próprio espaço vetorial:
texto → um modelo
imagem → outro
áudio → outro
O problema é que esses espaços não “conversam” entre si.
Se quisermos, por exemplo, buscar uma imagem a partir de uma descrição em texto, primeiro temos que criar um pipeline intermediário (gerar legendas, transcrever áudio, converter tudo para uma mesma representação).
Isso aumenta a complexidade e pode levar à perda de informação.
Na prática, construir sistemas multimodais significava montar um quebra-cabeça de modelos diferentes.
E é ai que surge o Gemini Embedding 2!
O que é o Gemini Embedding 2?

É um único modelo de embeddings que coloca texto, imagem, áudio, vídeo e documentos no MESMO espaço vetorial.
Em vez de tratar cada modalidade separadamente, o modelo projeta texto, imagens, áudio, vídeo e documentos diretamente no mesmo espaço semântico.
Isso elimina a necessidade de etapas intermediárias e permite comparar diferentes tipos de dados de forma nativa.
Na prática, isso abre possibilidades bastante naturais:
buscar uma imagem a partir de um texto
encontrar um áudio com base em uma imagem
comparar documentos com perguntas faladas
combinar texto e imagem em uma única representação
Tudo isso sem pipelines complexos e sem conversões artificiais.
Por que isso importa
A principal mudança aqui não é apenas técnica, é estrutural.
Antes, construir sistemas desse tipo envolvia múltiplos modelos, etapas de pré-processamento e integração entre diferentes representações.
Agora, grande parte disso pode ser reduzida a um fluxo muito mais simples:
gerar embedding → comparar → recuperar resultado
Além disso, o modelo trabalha com significado, não apenas com palavras. Isso permite capturar nuances que abordagens baseadas em keywords simplesmente não conseguem alcançar.
Um exemplo para começar
Vamos ver na prática um exemplo bem simples.
Imagine um pequeno conjunto de imagens: pizza, hamburger, sushi, macarrão e bolo. Vamos fazer uma busca semântica nas imagens em linguagem natural (texto).
Primero, vamos importar as bibliotecas necessárias:
from google import genai
from google.genai import types
import requests
from sklearn.metrics.pairwise import cosine_similarity
from IPython.display import display, ImageE agora, baixar algumas imagens:
images = {
"pizza": "https://images.pexels.com/photos/825661/pexels-photo-825661.jpeg",
"burger": "https://images.pexels.com/photos/1639557/pexels-photo-1639557.jpeg",
"sushi": "https://images.pexels.com/photos/357756/pexels-photo-357756.jpeg",
"pasta": "https://images.pexels.com/photos/1279330/pexels-photo-1279330.jpeg",
"cake": "https://images.pexels.com/photos/291528/pexels-photo-291528.jpeg",
}Agora, vamos instanciar o modelo. Você vai precisar criar uma API_KEY no Google Ai Studio.
import os
os.environ["GEMINI_API_KEY"] = "API_KEY"
client = genai.Client()
MODEL = "gemini-embedding-2-preview"Para cada imagem, vamos gerar um embedding.
image_embeddings = {}
for label, url in images.items():
img_bytes = requests.get(url).content
emb = client.models.embed_content(
model=MODEL,
contents=[
types.Part.from_bytes(
data=img_bytes,
mime_type="image/png"
)
]
).embeddings[0].values
image_embeddings[label] = (emb, url)Em seguida, fazemos uma busca com o texto.
A aplicação vai gerar embeddings do nosso texto de entrada, no nosso exemplo “macarrão”, e comparar com os embeddings das imagens, usando distância de coseno.
A seguir, vai retornar a imagem mais similar ao nosso texto de entrada.
query = "macarrão"
query_emb = client.models.embed_content(
model=MODEL,
contents=query
).embeddings[0].values
# encontrar imagem mais similar
best_label, best_score, best_url = None, -1, None
for label, (emb, url) in image_embeddings.items():
score = cosine_similarity([query_emb], [emb])[0][0]
if score > best_score:
best_label, best_score, best_url = label, score, url
Vamos printar os resultados:
from IPython.display import HTML
print(f"Resultado: {best_label} (score={best_score:.3f})")
display(HTML(f'<img src="{best_url}" width="300">'))Resultado:

Voilá!! Funcionou 🎉🎉🎉
Com isso, temos uma busca multimodal!
Possibilidades na prática
Ao colocar diferentes tipos de dados no mesmo espaço semântico, abre-se um leque de aplicações mais naturais e diretas:
busca multimodal (texto ↔ imagem ↔ áudio ↔ vídeo)
sistemas de RAG que incorporam documentos, imagens e áudio
recomendação baseada em conteúdo real, não apenas metadata
análise de dados complexos, como informações clínicas multimodais
organização e indexação de grandes volumes de mídia
E, talvez o mais importante: tudo isso pode ser construído com uma arquitetura significativamente mais simples.
Conclusão
O avanço aqui não está apenas na capacidade do modelo, mas na simplificação que ele traz.
Durante muito tempo, o desafio foi fazer diferentes tipos de dados “conversarem”. Criamos camadas, adaptações e pipelines para tentar alinhar essas representações.
Agora, esse alinhamento já nasce no próprio modelo.
Quem quiser explorar mais, segue o repositório do Fabricio Carraro com mais exemplos:
👉 https://github.com/fabriciocarraro/Gemini-Embedding-2-Complete-Guide (se você gostou, não esquece de deixar uma estrela!)