


Executando modelos localmente com LM Studio
Explore todo o poder da IA no seu próprio computador com o LM Studio

No cenário atual de Inteligência Artificial, a capacidade de executar modelos localmente oferece vantagens significativas em termos de privacidade, controle de dados e flexibilidade.
Dando continuidade à nossa série de posts sobre como executar modelos localmente, sem depender de APIs externas, hoje exploraremos as funcionalidades do LM Studio.
Neste post, mostramos algumas etapas e dicas para começar a usar o LM Studio para executar modelos localmente.
Principais recursos do LM Studio
O LM Studio oferece várias funcionalidades e recursos, como:
Personalização dos parâmetros do modelo: Isso permite ajustar a temperatura, tokens máximos, penalidade de frequência e outras configurações.
Histórico de bate-papo: permite salvar prompts para uso posterior.
Parâmetros e dicas de interface do usuário: você pode passar o mouse sobre os botões de informações para pesquisar parâmetros e termos do modelo.
Multiplataforma: o LM Studio está disponível nos sistemas operacionais Linux, Mac e Windows.
Verificação de especificações da máquina: O estúdio LM verifica as especificações do computador, como GPU e memória, e relata os modelos compatíveis. Isso impede o download de um modelo que pode não funcionar em uma máquina específica.
AI Chat e Playground: converse com um grande modelo de linguagem em um formato de bate-papo e experimente vários LLMs carregando-os simultaneamente.
Servidor de inferência local para desenvolvedores: permite que os desenvolvedores configurem um servidor HTTP local semelhante à API da OpenAI.
Instalação do LM Studio
Você deve fazer o download da aplicação conforme seu sistema operacional, acessando este endereço: https://lmstudio.ai, e instalar conforme as instruções.
Carregar um Modelo
O próximo passo é carregar os modelos de linguagem que você quer executar. A página inicial apresenta os principais LLMs disponíveis, além de exibir uma barra de pesquisa para filtrar modelos específicos de diferentes provedores de IA.
Neste tutorial, vamos utilizar o Phi3-mini-4k-instruct:
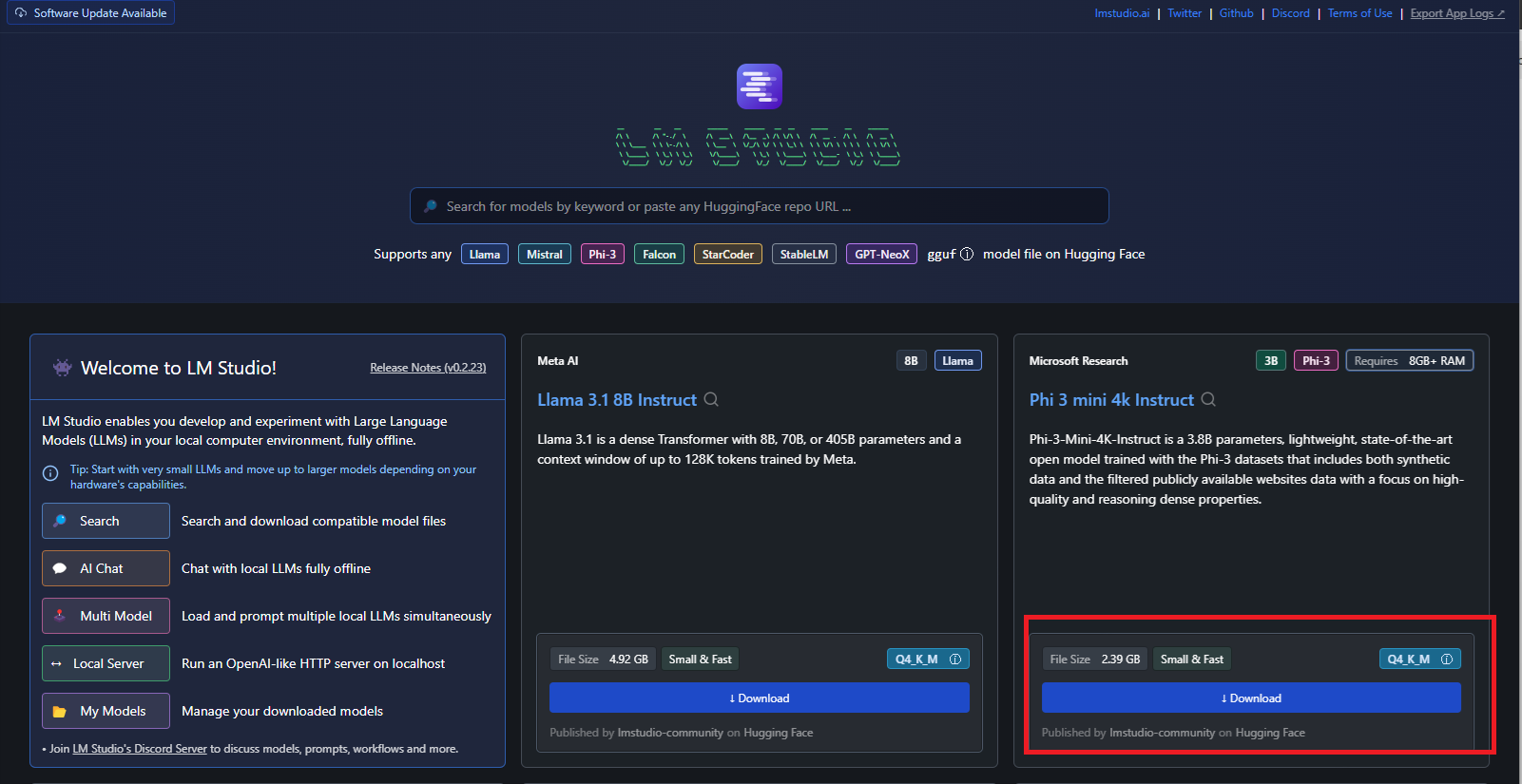
O Phi-3 da Microsoft é um modelo de linguagem pequeno que combina aprendizado profundo e técnicas de inteligência artificial para gerar texto, compreender contextos complexos e oferecer respostas mais precisas, promovendo uma interação mais natural entre humanos e máquinas.
Inicar Conversa
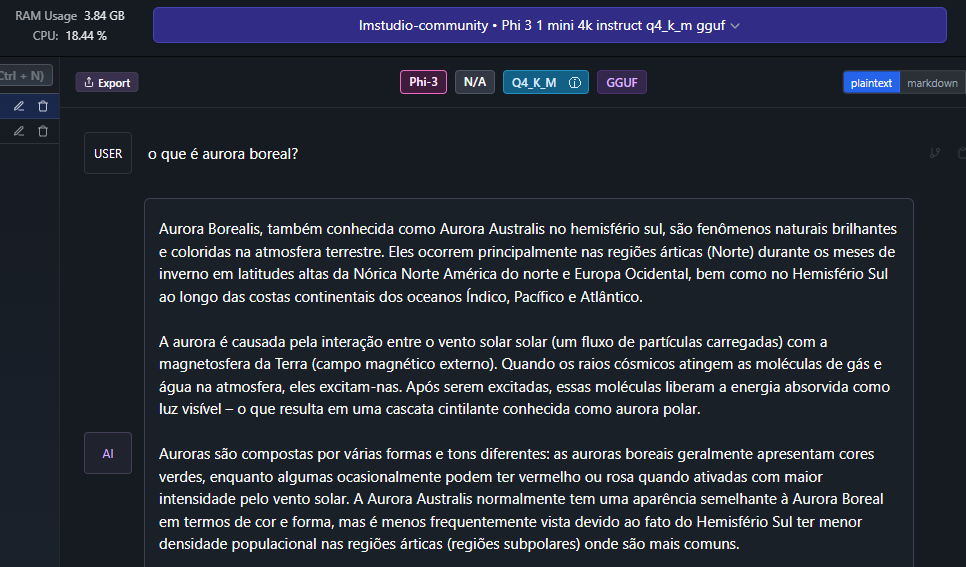
Basta clicar no ícone de balão para iniciar uma conversa e selecionar o modelo que você deseja conversar, no nosso caso, o Phi3.
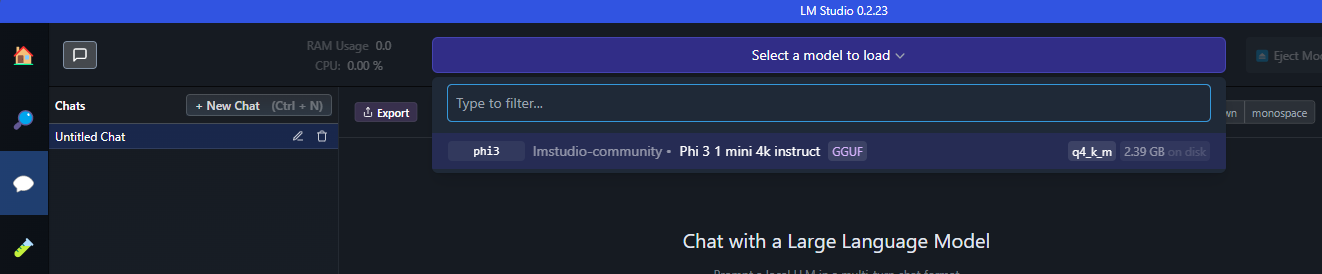
A partir de agora, você já consegue conversar com seu modelo!!
Configurando um servidor local
Com apenas um clique, você pode configurar um servidor HTTP local para inferência, semelhante à API da OpenAI.
Basta acessar o menu de flechas, como a imagem abaixo, e clicar para Iniciar o Servidor.
Ele vai executar na porta 1234 por padrão, mas você pode alterar se desejar.
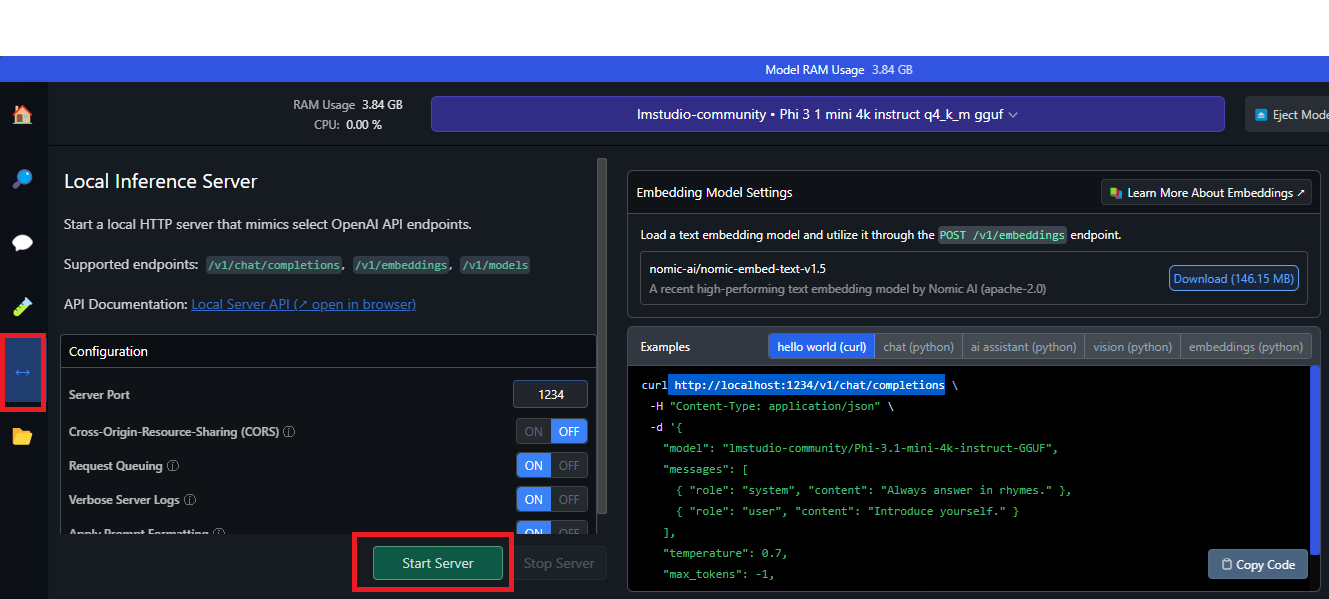
O servidor local fornece exemplos de solicitações de cliente Curl e Python. Com esse recurso, é possível criar um aplicativo de IA que usa o LM Studio para acessar um LLM específico.
Caso você já tenha uma aplicação existente que acessa a uma API da OpenAI, por exemplo, basta modificar a URL base para apontar para seu host local (localhost).
Você pode copiar o comando de exemplo e testar em seu computador!
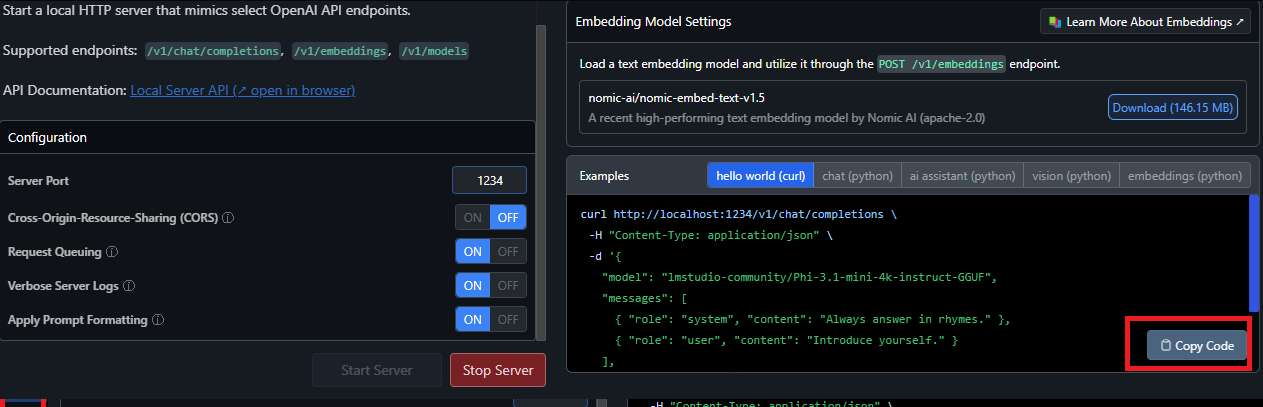
Para mais detalhes sobre a API, consulte a documentação.
Espero que tenham gostado! Até o próximo post!!