


DeepSeek: O que é e por que está chamando tanta atenção?
Novo modelo chinês promete desempenho de ponta com custo reduzido em comparação a modelos proprietários

A área dos grandes modelos de linguagem (LLMs) tem evoluído rapidamente, aproximando-se cada vez mais de um nível avançado de inteligência.
Na semana passada, um novo modelo de IA ganhou muito destaque. DeepSeek-R1, desenvolvido pela startup chinesa DeepSeek, é um modelo inovador que fortalece suas capacidades de raciocínio através do aprendizado por reforço (RL), sem depender exclusivamente do ajuste fino supervisionado.
O modelo mantém performance comparável aos modelos mais avançados em tarefas complexas de raciocínio e codificação, como o OpenAI-o1, com um custo de treinamento muito menor.
Além disso, os modelos da empresa são de código aberto, democratizando o acesso à IA e abrindo portas para pesquisas e para pequenas empresas e pesquisa.
Afinal, o que é o DeepSeek?
O modelo que está se destacando nas mídias é o DeepSeek-R1, um modelo que tem como objetivo aprimorar a capacidade de raciocínio dos LLMs utilizando um treinamento em múltiplas etapas.
Seu predecessor, o DeepSeek-R1-Zero, foi treinado diretamente via aprendizado por reforço em larga escala RL, sem o ajuste fino supervisionado (SFT) como etapa preliminar, já demonstrando capacidades de raciocínio notáveis. Embora o DeepSeek-R1-Zero tenha desenvolvido comportamentos poderosos e intrigantes de raciocínio, apresentou desafios como baixa legibilidade e mistura de idiomas.
Para solucionar esses problemas e aprimorar ainda mais o desempenho do raciocínio, o DeepSeek-R1 introduziu uma abordagem refinada, incluindo um "cold start" com dados iniciais e um treinamento supervisionado intermediário.
Principais Diferenciais do DeepSeek-R1
A seguir, vamos ver as principais características do DeepSeek.
Aprendizado por Reforço Puro
O DeepSeek-R1-Zero mostrou que um modelo pode desenvolver habilidades de raciocínio sem necessidade de ajuste fino supervisionado. Isso significa que o modelo aprende a pensar por conta própria, seguindo incentivos de recompensa.
Pipeline de Treinamento Multi-Estágios
Já o DeepSeek-R1 inicia seu treinamento com um pequeno conjunto de dados de alta qualidade para evitar oscilações iniciais no RL. Em seguida, passa por múltiplos estágios de RL e ajuste fino supervisionado.
Distilação para Modelos Menores
O DeepSeek-R1 também foi utilizado para destilação do seu conhecimento para modelos menores, como versões baseadas em Qwen e Llama. Isso possibilita modelos mais eficientes, sem perder a capacidade de raciocínio.
Resultados
Nos benchmarks de raciocínio, o DeepSeek-R1 atingiu resultados comparáveis ao OpenAI-o1-1217, demonstrando excelência em tarefas como matemática, codificação e conhecimento geral.
Ele também obteve 97,3% no MATH-500 e se destacou em competições de programação, superando 96,3% dos participantes no Codeforces.
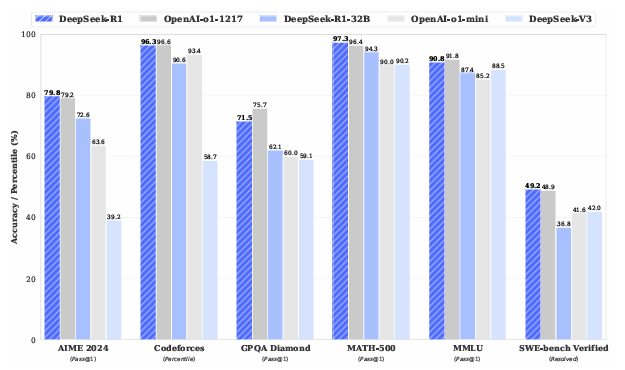
Na figura acima, podemos ver o desempenho do DeepSeek-R1 em comparação com outros modelos em diversos benchmarks, onde podemos ver que obteve resultados similares ao modelo OpenAI-o1, com resultados melhores em 3 de 6 avaliações.
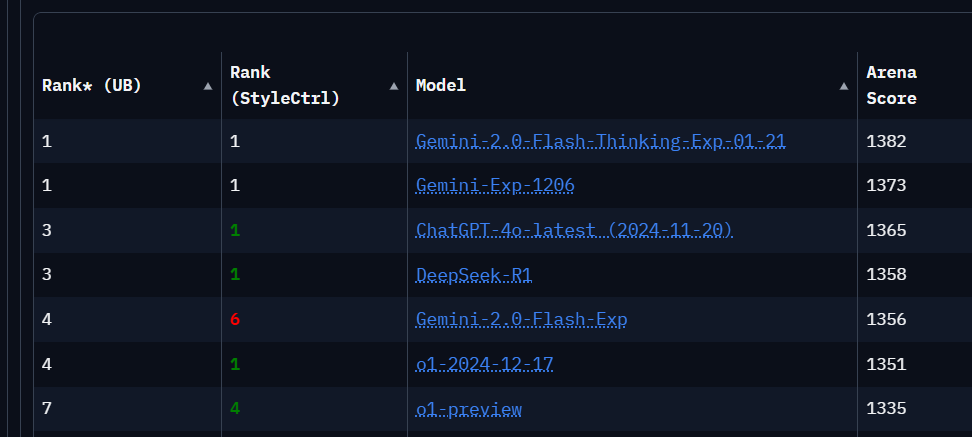
Já no ChatbotArena, uma plataforma na web onde podemos comparar vários LLMs em batalhas interativas, o DeepSeek-R1 aparece em 3o. lugar empatado com o ChatGPT-4o-latest (ficando atrás apenas dos poderosos Gemini-Exp da Google).
Como executar localmente o DeepSeek?
Para executar o DeepSeek no nosso computador, sem a necessidade de GPUs, podemos usar um modelo destilado com menos parâmetros.
Continue a ler com uma experiência gratuita de 7 dias
Subscreva a Explorando a Inteligência Artificial para continuar a ler este post e obtenha 7 dias de acesso gratuito ao arquivo completo de posts.