
Criando Chatbots com RAG usando LangChain
Parte 2 da série "Tudo o Que Você Precisa Saber Sobre LangChain (Antes de Começar um Projeto com IA)"

Na última edição, começamos nossa série sobre LangChain, uma das bibliotecas mais poderosas para construir aplicações que combinam modelos de linguagem com dados externos.
Neste artigo, vamos ver como construir um chatbot completo que utiliza RAG (Retrieval-Augmented Generation) para fornecer respostas precisas baseadas em documentos específicos.
Esta nova abordagem está inovando a forma como os sistemas de IA geram respostas, combinando o poder dos grandes modelos de linguagem (LLM) com a precisão de bases de dados específicas.
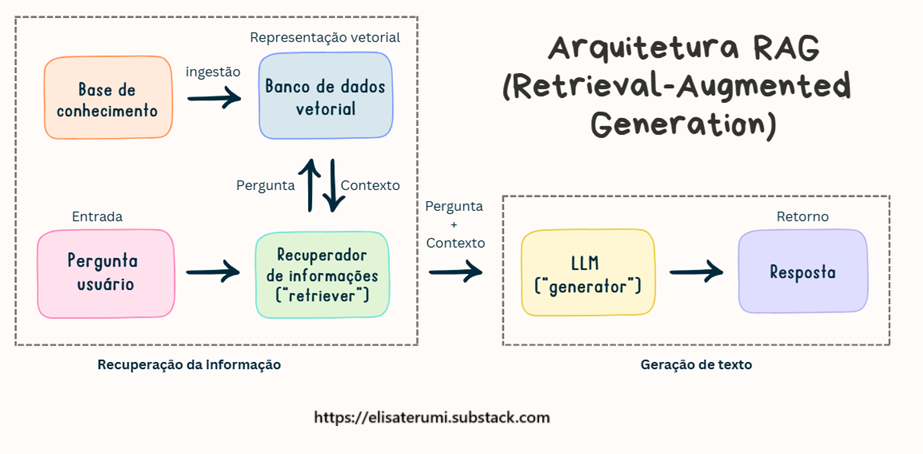
O que é RAG?
RAG em português seria algo como “Geração Aumentada por Recuperação”. A ideia é simples, mas poderosa: em vez de um LLM responder só com base no que “sabe” internamente, ele busca informações relevantes em uma base de dados ou documentos antes de gerar a resposta.
Isso aumenta muito a precisão e contextualização.
Essa arquitetura combina dois componentes essenciais: um sistema de recuperação de informações e um modelo de geração de linguagem. Em vez de depender apenas do conhecimento interno do modelo, o RAG busca informações relevantes em bases de dados externas antes de gerar uma resposta.
Imagine um especialista que, antes de responder a uma pergunta complexa, consulta sua biblioteca pessoal para encontrar as informações mais precisas e atualizadas. É exatamente isso que o RAG faz, mas de forma automatizada e em velocidade computacional.
Me acompanhe no LinkedIn e no Instagram pra mais conteúdos como esse! 😉
Como funciona o RAG?
O processo do RAG pode ser dividido em três etapas principais:
1. Recuperação (Retrieval)
Quando uma pergunta é feita, o sistema primeiro busca em uma base de dados vetorial por documentos ou trechos de texto relevantes. Esta busca utiliza técnicas de similaridade semântica, encontrando conteúdo que está relacionado ao contexto da pergunta, mesmo que não contenha as palavras exatas.
2. Aumentação (Augmentation)
Os documentos recuperados são então combinados com a pergunta original, criando um contexto enriquecido. Este contexto fornece ao modelo de linguagem informações específicas e atualizadas sobre o tópico em questão.
3. Geração (Generation)
Finalmente, o modelo de linguagem utiliza tanto seu conhecimento interno quanto as informações recuperadas para gerar uma resposta precisa e contextualmente relevante.
O fluxo básico do chatbot é:
Receber a pergunta do usuário
Recuperar documentos relevantes em uma base de conhecimento (como um banco de dados, PDF, artigos, etc).
Passar esses documentos e a pergunta para o modelo de linguagem, que gera uma resposta baseada naquele contexto específico.
Entregar a resposta para o usuário.
Por que usar LangChain para isso?
LangChain oferece componentes prontos para montar esse pipeline de forma modular e escalável:
Retriever: para buscar as informações certas, usando vetores, embeddings e bancos especializados.
Chain: para conectar a recuperação com o modelo de geração.
Memory: para armazenar o contexto e histórico do diálogo, deixando o chatbot mais natural. (vamos ver futuramente!)
Exemplo - página Wikipedia
Imagine que você tem uma base de documentos sobre seu produto.
Com LangChain, você pode criar um chatbot que, ao receber uma pergunta, busca os trechos mais relevantes e gera uma resposta detalhada, mesmo que a pergunta seja muito específica.
Para exemplificar, vamos buscar uma página da Wikipedia sobre “bicho-preguiça“, usando a biblioteca WikipediaLoader.
from langchain.document_loaders import WikipediaLoader
# Carregar conteúdo da Wikipedia
loader = WikipediaLoader("Bicho-preguiça", lang="pt", load_max_docs="1", doc_content_chars_max="10000")Agora, vamos dividir o documento recuperado em pedaços menores, os chunks, usando RecursiveCharacterTextSplitter.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_documents(docs)Vamos gerar embeddings (representação vetoral) dos chunks usando o modelo multilíngue sentence-transformers/distiluse-base-multilingual-cased-v2, e armazenar em um BD vetorial (FAISS).
A seguir, criamos nosso recuperador de informações (retriever).
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/distiluse-base-multilingual-cased-v2")
# Armazenando no FAISS
vectorstore = FAISS.from_documents(texts, embeddings)
# Criação do retriever
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})Agora, vamos criar nosso chatbot com ChatGoogleGenerativeAI, usando o modelo Gemini-1.5-flash.
from langchain.chains import RetrievalQA
from langchain_google_genai import ChatGoogleGenerativeAI
# Configure sua chave Gemini
os.environ["GOOGLE_API_KEY"] = ""
# Criação da chain RAG com Gemini
llm = ChatGoogleGenerativeAI(model="models/gemini-1.5-flash", temperature=0.3)
# passamos nosso retriever aqui
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# Pergunta do usuário
# A resposta será baseada nas informações da páginda da Wikipedia
pergunta = "Quais espécies de bicho preguiça no Brasil?"
resposta = qa_chain.run(pergunta)
print("Resposta:", resposta)A resposta:
Resposta: No Brasil, existem as seguintes espécies de preguiças de três dedos:
* Preguiça-comum (*Bradypus variegatus*)
* Preguiça-de-bentinho (*Bradypus tridactylus*)
* Preguiça-de-coleira (*Bradypus torquatus*)
Além dessas, também são encontradas no Brasil as preguiças de dois dedos:
* Preguiça-de-dois-dedos (*Choloepus hoffmanni*)
* Preguiça-real (*Choloepus didactylus*)Com apenas algumas linhas, montamos um chatbot com acesso à uma base de dados exerna!
🚀 Para acessar o código com mais exemplos de uso do LangChain, visite nossa área de Notebooks Colab, com notebooks prontos para você executar! Procure por LangChain-chatbot-RAG.ipynb.
Conclusão
A técnica de RAG marca um avanço importante na construção de sistemas de IA mais precisos e confiáveis. Ao unir modelos de linguagem com bases de dados específicas, oferece uma solução eficaz para os limites da IA tradicional.
O LangChain oferece uma plataforma robusta para construir chatbots com RAG, permitindo criar soluções sofisticadas com código relativamente simples. A arquitetura modular facilita a customização e expansão do sistema conforme suas necessidades específicas.
Com o exemplo apresentado neste artigo, temos uma boa base para construir chatbots que podem responder perguntas precisas baseadas em nossos próprios documentos.
OBS: O intuito desse artigo é educacional, com um exemplo simples para facilitar o entendimento. Para implementações em produção, considere sempre aspectos como segurança, escalabilidade e monitoramento.
O próximo passo é experimentar com diferentes configurações, explorar outros tipos de document loaders e considerar integrações com interfaces web para criar uma experiência de usuário completa.
Este é o segundo artigo da nossa série sobre LangChain. Acompanhe os próximos posts, onde vamos explorar como criar chatbots com memória, interface (Streamlit) e chamadas de agentes!
Parabens pelo artigo. Elisa, publica um artigo desses usando GraphRAG :)